
This cosmological hydrodynamic simulation produced by CRK-HACC is actually a snapshot of the universe. A large cluster is zoomed in. The targeted simulation on Frontier will be 140 times larger, with hundreds of thousands of clusters. Credit: Michael Buehlmann, of the HACC team at Argonne National Laboratory
Cholla, HACC, and Parthenon are ready to launch the exascale era of computational astrophysics.
A trio of new and improved cosmological simulation codes was unveiled in a series of presentations at the annual April Meeting of the American Physical Society in Minneapolis, MN. Chaired by the Oak Ridge Leadership Computing Facility’s (OLCF’s) Director of Science Bronson Messer, the session covering these next-generation codes heralds a new era of exascale computational astrophysics, which promises to advance our understanding of the universe with models of unprecedented scale and resolution.
Powered by the incoming generation of exascale (a billion-billion floating point operations per second) supercomputers, the updated versions of HACC, Cholla, and Parthenon are the culmination of years of work by developers to prepare their codes for exascale’s thousandfold increase from petascale computing speed. With their successful early runs on the OLCF’s Frontier supercomputer located at the US Department of Energy’s (DOE’s) Oak Ridge National Laboratory (ORNL), the codes are ready to explore virtual domains of the cosmos that were previously beyond science’s reach.
“These newly improved astrophysical codes provide some of the clearest demonstrations of the most empowering features of exascale computing for science,” said Messer, a computational astrophysicist, distinguished scientist at ORNL, and member of the team that won a 2022 R&D 100 Award for the Flash-X software. “All these teams are simulating an array of physical processes happening on scales ranging over many orders of magnitude—from the size of stars to the size of the universe—while incorporating feedback between one set of physics to others and vice versa. They represent some of the most challenging problems that will be attacked on Frontier, and I expect the results to be remarkably impactful.”
HACC/CRK-HACC
HACC (Hardware/Hybrid Accelerated Cosmology Code) is a veteran simulator of the cosmos that focuses on large-scale structure formation in the dark sector, which includes dark energy, dark matter, neutrinos, and the origins of primordial fluctuations.
HACC’s origins date back to the Roadrunner supercomputer at Los Alamos National Laboratory, which was the first machine to break the petaflop barrier (1 thousand-million-million floating-point operations per second) in 2008. Currently being developed by researchers at Argonne National Laboratory with support from the DOE’s Exascale Computing Project (ECP), HACC has been optimized for Frontier’s AMD Instinct™ GPU accelerators, and optimizations for Argonne’s Aurora supercomputer and its Intel GPUs are in the works.
GPUs were introduced to supercomputers in 2012 with the OLCF’s Titan and its NVIDIA Kepler processors, which tackled computationally intensive math problems while the CPUs efficiently directed tasks. More than 10 years later, GPUs have become increasingly important in accelerating complex computations.
“The old mantra for GPU machines used to be ‘GPU accelerate,’ which means you would often send a bunch of small kernels asynchronously to the GPU and they would chug away—you’d hide things there,” said Nicholas Frontiere, a computational scientist at Argonne and co-team leader for CRK (Conservative Reproducing Kernel)-HACC development, which adds hydrodynamics modelling. “I feel that approach has changed. Today, the goal is what I like to call ‘GPU resident,’ meaning the GPU is as big as the memory space on your host side.”
With development support from the ECP’s ExaSky project, HACC leverages exascale’s increased computing abilities by packing in more physics models than the original code’s gravity solver. As survey data of the universe becomes more detailed and complex, the more sophisticated such simulation tools must become to keep pace. Astrophysicists use observations to validate the virtual mock-ups of the universe, constraining parameters used in the simulations; if their measurements don’t match the simulation’s, then there’s a disparity to resolve.
One of HACC’s biggest goals is to provide survey-scale mock catalogs for current large-scale, large-structure formation surveys such as the Rubin Observatory LSST, SPHEREx, and CMB-S4.
“Being able to mock those surveys requires a tremendous amount of volume to simulate and a lot of physics to compute. And none of these things are achievable with the previous generation of supercomputers,” Frontiere said. “It’s only at the exascale regime that you can really start simulating the volumes that are required for these types of surveys.”
HACC’s future sounds pretty straightforward: more is better.
“The next horizon for us is including more and more detailed astrophysics in our simulations so that even with the same volumes and simulations, you can get better resolution,” Frontiere said. “So, most of our research is really adding more physics, which is something we would never have been able to consider without running at the scales we are now.”
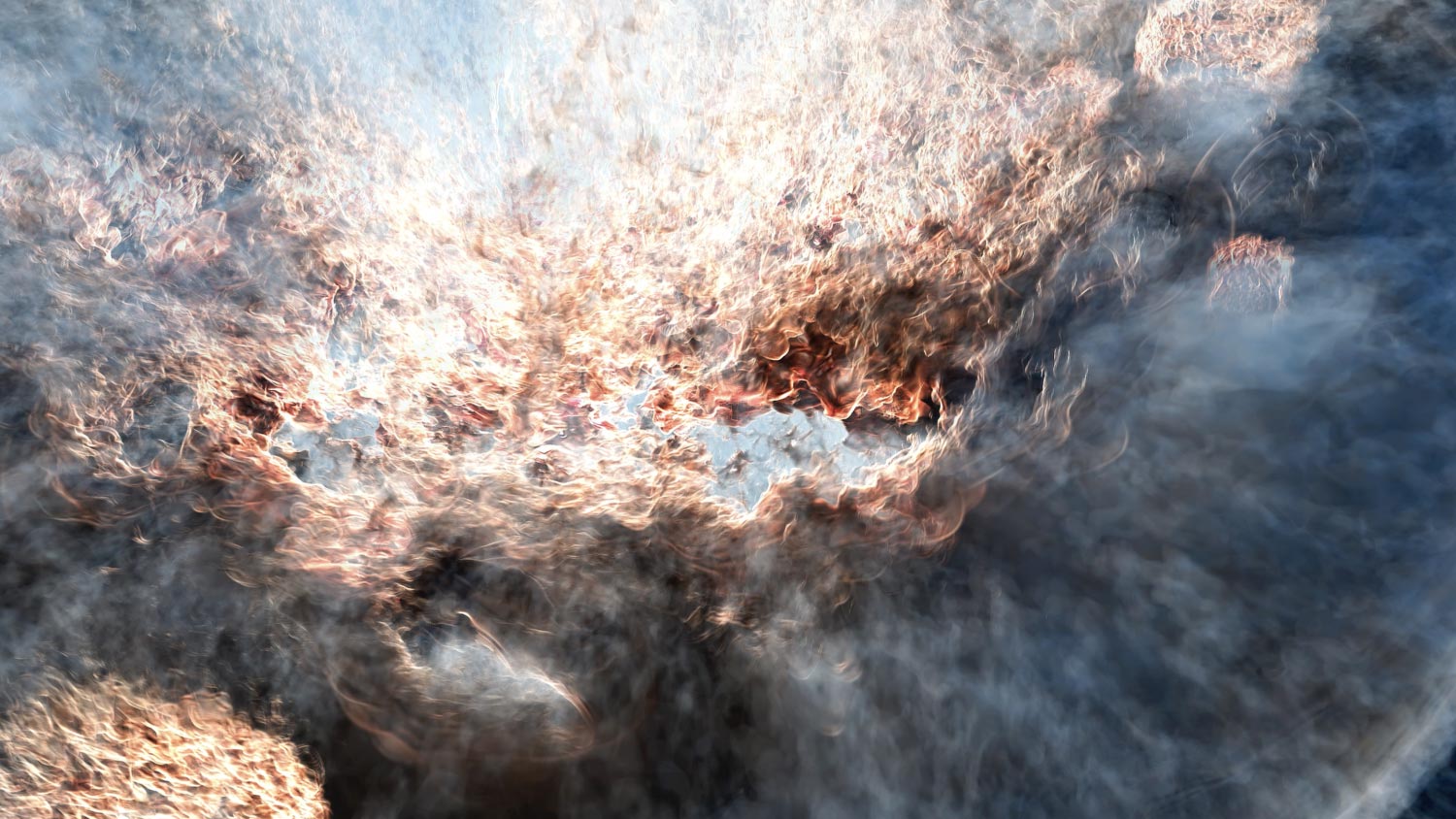
A visualization of an outflow of galactic wind at a single point in time using Cholla. Credit: Evan Schneider, University of Pittsburgh
Cholla
Initially developed in 2014 by an astrophysics doctoral student at the University of Arizona, the GPU-accelerated fluid dynamics solver Cholla (Computational Hydrodynamics On ParaLLel Architectures) was intended to help users better understand how the universe’s gases evolve over time. That student, Evan Schneider, is now an assistant professor in the University of Pittsburgh’s Department of Physics and Astronomy, and Cholla has become an astrophysics powerhouse.
Schneider intends to use Cholla to simulate an entire galaxy the size of the Milky Way at the scale of a single star cluster—modeling a massive galaxy at this resolution would be a first for computational astrophysics. Doing so will require more than just optimizing the code to run on Frontier, an effort that was supported by the Frontier Center for Accelerated Application Readiness (CAAR) program.
“I’m interested in modeling galaxies. And a lot of astrophysics simulations, particularly cosmological simulations, are designed to have periodic boundary conditions. The code for that is relatively straightforward,” Schneider said. “But for these big galaxy simulations, we need them to have boundaries that resemble the boundary of the edge of a galaxy. And that’s not periodic, right? We had to do some intensive algorithmic work there just to figure out how to deal with gravity at the edge of our simulation domain.”
Additionally, Cholla needed to go far beyond its hydrodynamics roots to include the physics required to model an entire galaxy. Fortunately, as an open-source code, Cholla has also attracted helping hands on its way to exascale—in particular, those of Bruno Villasenor, who was studying dark matter as a doctoral student at the University of California, Santa Cruz. He and his PhD adviser, Brant Robertson, decided to use Cholla for their simulations of the Lyman-Alpha Forest, which is a series of absorption features formed as the light from distant quasars encounters material along its journey to Earth. But to do so required several more physics models. So, Villasenor integrated them into Cholla over the course of 3 years for his PhD dissertation.
“Bruno added gravity, added particles, and added cosmology so that we could do these big cosmological boxes. And so that really changed Cholla from a pure fluid dynamics code into an astrophysics code,” Schneider said.
Now, with its new capabilities powered by Frontier’s exascale speed, Cholla is poised to accomplish breakthrough work that was inconceivable on previous systems.
“Resolution is the name of the game. The holy grail for me is to be able to run a simulation of a Milky Way–sized galaxy with individual supernova explosions resolved. And so far, people have only been able to do that for tiny galaxies because you must have a high-enough resolution to cover the entire disk at something like a parsec scale,” Schneider said. “It sounds simple because it is just the difference between running a simulation with 4,0003 cells and a simulation with 10,0003 cells, but that’s roughly 60 billion cells to 1 trillion cells, total. You really need the jump to exascale to be able to do that.”
That leap is about to happen, and Schneider and her team can’t wait to get started.
“It’s really exciting to work on building something for a long time and then finally being able to see it at scale. Everybody’s just excited to see what we’re going to be able to do,” Schneider said.

AthenaPK (with the Parthenon framework) created this simulation of a cold, dense cloud of plasma hit by a diffuse, hot, supersonic wind: (top left) cloud density overlaid with the simulation mesh that is finer around the cloud; (bottom left) streamlines of the wind (white) with areas of strong vorticity (orange), leading to turbulence in the wake; (bottom right) magnetic field lines drape around the cloud, shielding it from the wind; and (top right) the observation of the jellyfish galaxy ESO 137-001, which exhibits similar behavior. Galaxy image credit: NASA/ESA Hubble Space Telescope observations with data from the Chandra X-ray Observatory. Credit: Philipp Grete/AthenaPK
Parthenon
Back in 2018, Michigan State University postdoctoral researcher Philipp Grete and then graduate student Forrest Glines were attending a boot camp for the Kokkos Programming Model, and their thoughts were focused on the near future of computational astrophysics. With exascale-class supercomputers arriving soon, how would current simulation codes be able to run well on the yet-to-be-finalized hardware?
The Kokkos programming ecosystem, which promises performance portability across different computer platforms, could be one solution. So, Glines (now a Metropolis Postdoctoral Fellow at Los Alamos National Laboratory) and Grete (now a Marie Skłodowska-Curie Actions Postdoctoral Fellow at the Hamburg Observatory) brought the modern, open-source Athena++ magnetohydrodynamics code to the bootcamp to see if Kokkos could deliver on its promise of portability.
“It actually turned out to be true. In a comparatively short time, we were able to make part of the code base work on GPUs— specifically for simulations with a fixed, static uniform grid,” Grete said. “It eventually sparked the larger, cross-institutional Parthenon project.”
At its core, the open-source Parthenon is an adaptive mesh refinement code for grid-based simulations with the ability to refine resolution only in a certain region of a simulation grid to increase the speed and accuracy of its calculations. The team uses Parthenon in their code, now called AthenaPK, to simulate different astrophysical systems—primarily turbulence and feedback from active galactic nuclei (AGN) jets.
But what makes Parthenon unique in exascale-class computational astrophysics is its performance portability via Kokkos, which allows Parthenon to serve as a framework for other fluid dynamics codes to leverage mesh refinement no matter what architecture they’re running on—NVIDIA GPUs, AMD GPUs, Intel GPUs, Arm CPUs, or just traditional CPUs.
“Parthenon’s performance portability allows researchers to run on any supercomputer platform that the underlying Kokkos framework supports. Developers don’t have to worry about reimplementing their simulation code for each new platform,” Glines said. “The faster codes driven by Parthenon allow more simulations with higher resolution and thus higher-fidelity models of the physical systems they’re studying.”
Parthenon is already being used in a variety of codes, including Phoebus, which is a general relativistic magnetohydrodynamics (GRMHD) code being developed at Los Alamos National Lab, and KHARMA, which is another GRMHD code being developed at the University of Illinois Urbana-Champaign. KHARMA was already used in an Innovative and Novel Computational Impact on Theory and Experiment (INCITE) project last year.
Meanwhile, the team’s AthenaPK software is being used in a 2023 INCITE project on Frontier to study “feedback and energetics from magnetized AGN jets in galaxy groups and clusters.”
“We’re particularly excited about our own project because without Parthenon and without AthenaPK, the computational physics challenge—talking about resolving both the jet and the surrounding diffuse plasma at sufficiently high resolution to study self-regulation—would not have been possible on any other machine or with any other code that we are aware of right now,” Grete said.


{kind=link}
{kind=link}